To be able to write or modify a program that analyzes the metadata of a packed program in an attempt to determine visualizable information about packed samples of malware, one has to have a deep understanding of how the Portable Executable file format works. Today, I set out to get a better understanding and appreciation of this.
My information is mainly pulled from Wikipedia’s PE article and the official Microsoft PE specification. I also tie together some bits of information by analyzing the on-disk contents of both packed and unpacked samples of both clean and malicious executables.
Basics
A picture is worth a thousand words. The diagram of a PE from Wikipedia is an extremely valuable resource that helped me immensely with understanding offsets and locations of data relative to other locations of data. Follow along with this picture.

Microsoft loves the concept of backwards compatability. As such, every exectuable program generated for Windows technically runs on prior versions of Windows. The first part of the executable file format is a valid program stub for MS-DOS. All it does is tell you that you can’t run the program in DOS mode, but shrug! It’s still a valid DOS program.
Immediately after begins the Common Object File Format (COFF) headers. Note that Microsoft documents what all headers and header fields are as well as what data each should contain– and quite well, in my opinion. I only discuss the fields I believe are important for appreciating how packers work their magic. I will refer to each header chunk by the color in which Wikipedia’s diagram colors it.
Green section: COFF Header
- Signature: must be this or the file isn’t valid. That’s just how it is.
- Machine: contains magic numbers that identify the type of target machine. It’ll contain numbers (identified in the official docs) that correspond to, for example, x86 architectures, MIPS architectures, etc.
- NumberOfSections: This tells us the number of sections in the file. Because each section header is a static size, it also inadvertently tells us the size of the section table. I believe the section table is just a collection of metainformation about each section (i.e. one purple section header, per section).
Yellow section: Standard COFF Fields
- Magic: This tells us what kind of executable it is: PE32, PE32+ (ie. 64bit), or ROM.
- PE32: 0x10b
- PE32+: 0x20b
- ROM: 0x107
- SizeOfCode: Size of the actual instructions (i.e. the text section) (or it’s the sum of all the text sections)
- The packer may change these values to be nonsensical. I don’t know at this moment.
- SizeOfInitializedData: Size of initialized data.
- Initialized data is data that is initialized already. This includes global variables and local static variables that are set to nonzero values in the source code. Furthermore, this is often (but not necessarily) known as the .data segment within the executable.
-
SizeOfUninitializedData: Size of uninitialized data. This includes global or static variables that are assigned a value of 0 in the source code or do not have explicit initialization in the source code. I found this distinction here.
- AddressOfEntryPoint: Entry point. So this is how OllyDbg knows where to go. I’m sure this is required to include; otherwise Windows won’t be able to execute the program.
All programs have a preferred address in which they can be loaded into by the Windows loader. According to Wikipedia, Windows programs do not by default contain position-independent code (which means Windows program instructions cannot be moved internally to the program and expected to work properly). Instead, the programs are compiled to work directly with a preferred base address. Programs refer to this base address when referring to data, functions, etc within the program. If a program is already loaded at a specific base address, then Windows recalculates every one of those position-dependent instructions at runtime, for some other base address that is determined by the Windows loader to be free. Under ideal circumstances (i.e. no overlaps), this is the faster method as it can be heavily optimized. However, in reality, I’m sure that there are many times in which programs running simultaneously have overlapping preferred addresses and, as such, lose those optimizations, thus causing programs to be slower in this situation.
ELF– the Linux executable file format– does not do this. They can’t optimize in the same ways that Windows can, but they also won’t struggle if they can’t be loaded to a preferred address (and, matter of fact, I believe ELF by default has position independent code which means the entire concept of a preferred base address doesn’t even exist).
Red section: Windows Specific Fields
- ImageBase: the preferred load location. Must be a multiple of 64K (that is, 65536).
- SizeOfImage: the size (in bytes) of the image, including all headers, as the file is loaded in memory. I believe this can be used to help identify if something is packed. Not sure entirely yet, but I have a feeling it’s important.
Blue section: Data Directories Fields
I’m not sure if anything in this section is particularly notable yet.
Purple section: Section Headers
- Name: the name of this section– 8 bytes, UTF-8 encoded. If 8 char long, NOT null terminated.
- From what I can tell, this is directly manipulated by packers. It need not actually have any text in the section either, as some packers prove.
- VirtualSize: total size of section when loaded into memory.
- VirtualAddress: address of the first byte of this section relative to the image base.
- SizeOfRawData: Size of the initialized data on disk.
- PointerToRawData: Filei pointer to first page of teh section within this COFF file.
- When the section contains only uninitialized data, this should be set to 0.
The rest of the stuff in this header looks uninteresting or deprecated (often both simultaneously).
Special Section Names
Some sections are special and are treated accordingly by the Windows loader.
| Section name | Section Contents |
|---|---|
| .bss | Uninitialized data |
| .data | Initialized Data |
| .debug$X | debug information; differs for certain values of X |
| .idata | Import tables |
| .rdata | Read-only initialized data |
| .reloc | Image relocataions |
| .rsrc | Resource directory |
| .sbss | GP-relative uninitialized data See more related section types on Microsoft's docs. |
| .text | Exectuable code |
| .xdata | Exception information |
Information above was derived from Microsoft’s special section names documentation; see that page for more sections or more details.
Connecting the Dots
So, with all this being said, how do some legitimate files actually look? How do malicious files look? How do packed files look? Can we derive any signs that files are packed? These are questions I try to answer in this section of the post.
I use two programs to analyze the metadata of executables: PEView and PEiD. Note that I only explore 32 bit files for now. 64 bit will come later.
Starting off: Unpacked vs UPX-Packed command prompt
Let’s start off simple. I have taken cmd.exe from my Windows 7 box, copied it to my Linux box, and packed it with UPX. I then copied it back to my Windows box and compared the two.
Here’s a PEiD information image dump.
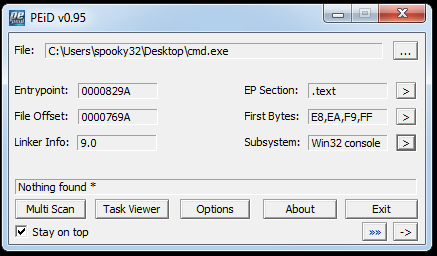
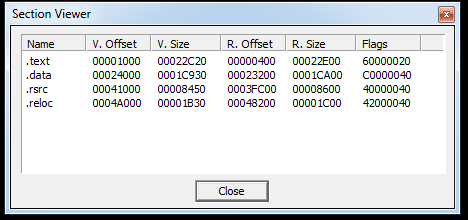
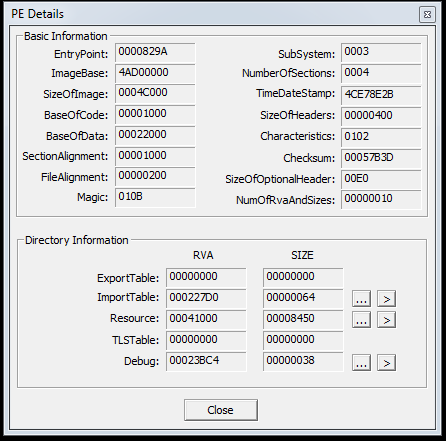
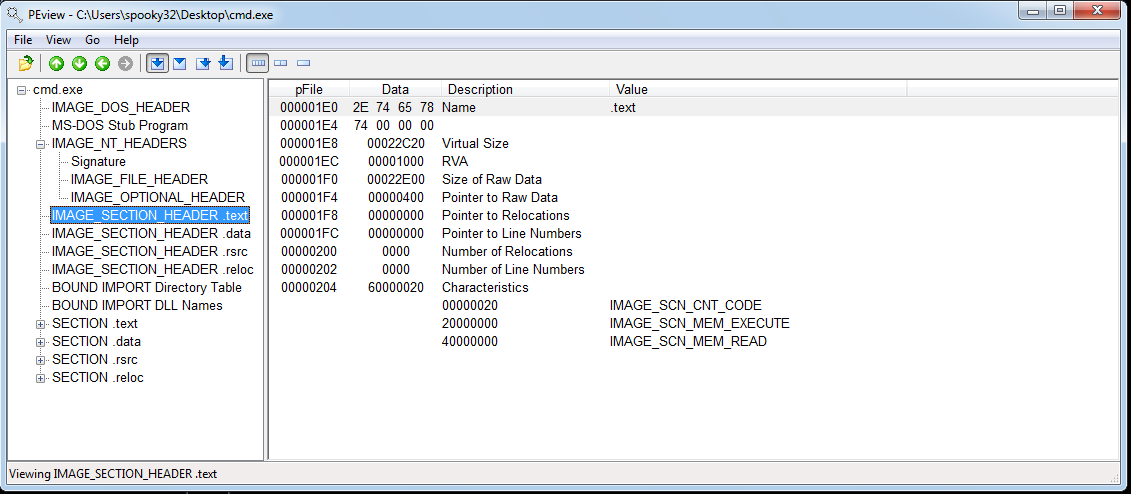
And we can find similar information out from PEview as well, but in a different way. PEview makes it easy to see specific values of headers.
And now, here are the corresponding clips of the packed version of CMD:
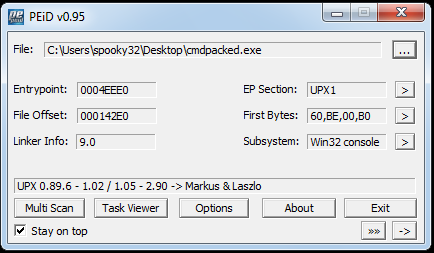
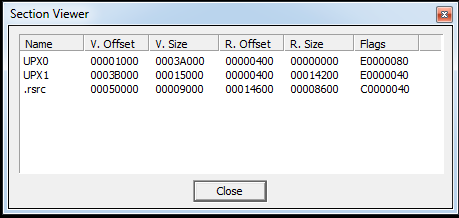
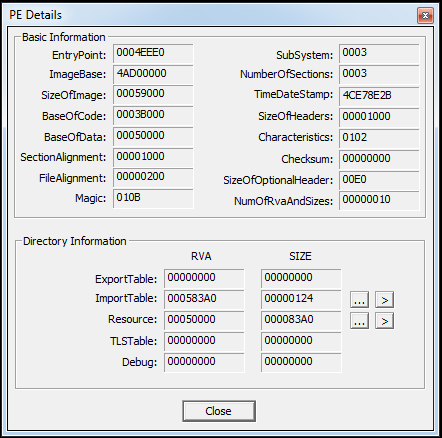
And the PEview details of the first section:
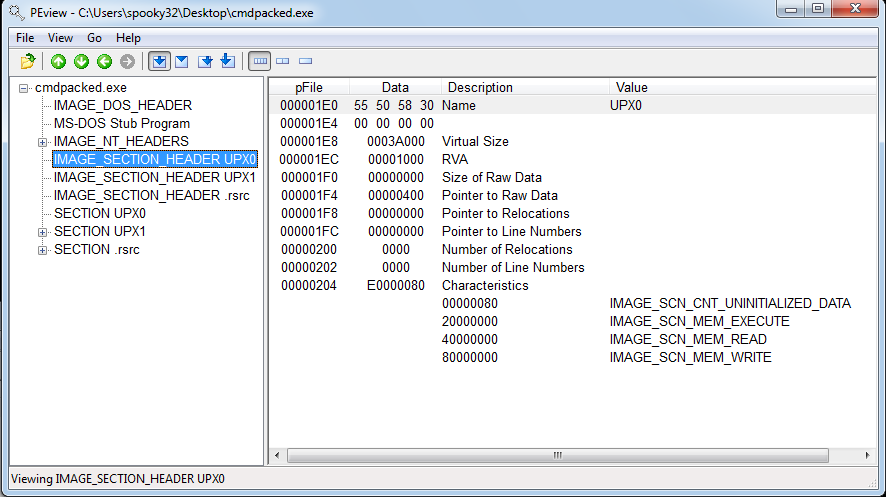
My observations:
-
Sections can be totally mangled and manipulated, as long as the entry point points to somewhere inside one of the sections.
-
Entry points can go within any section, at any point in that section. We can use PEiD and PEview together to view the raw data where the entry point begins. (Why this might be helpful, I don’t know; it is, however, interesting to me.)
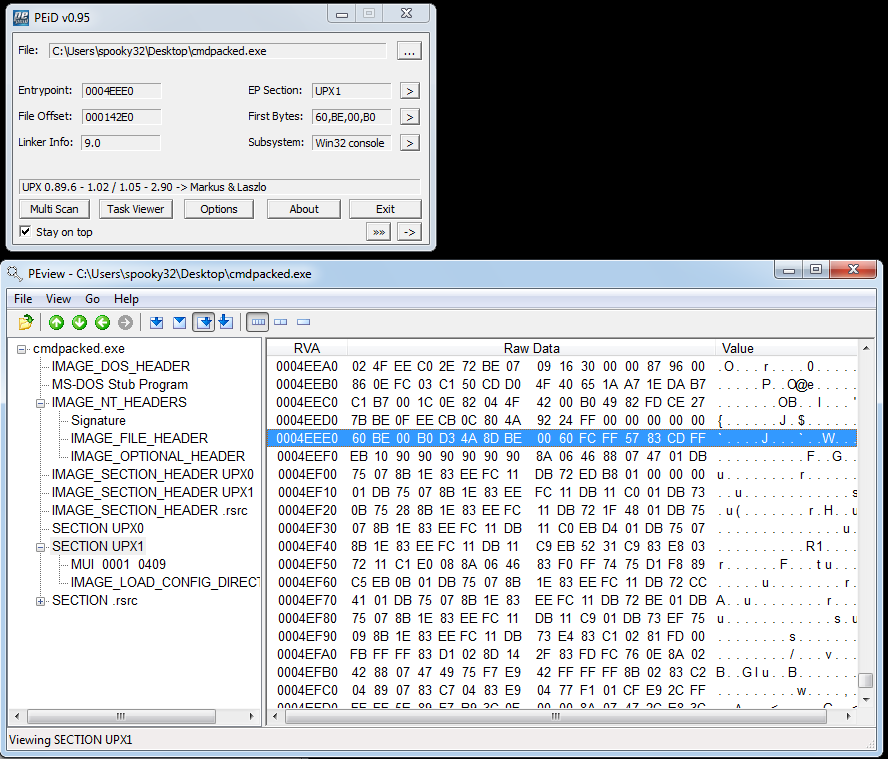
Notice that I needed to click the RVA button on PEview to get the corresponding entry point from PEiD to show up properly.
-
Prediction: Entry points should point to the .text section of an unpacked, unobfuscated binary– even if the binary is malicious.
- Raw sizes of 0 for sections (such as section UPX0) that have large virtual sizes is strange.
- Prediction: this is indicative of where the code is unpacked to at runtime.
- Normal behavior seems to indicate that the raw sizes and the virtual sizes of sections are about the same with the virtual size being slightly smaller than the raw size.
An unpacked, malicious executable
I’ve obtained a sample of cryptomining malware from VirusShare named VirusShare_3864106aa2b5e35062b436a39ad83382. It’s, as far as I can tell prior to now, unpacked. Will our observations about the nature of packed vs. unpacked executables thus far confirm this suspicion?
PEiD says its entry point is within the .text section, which corresponds to observations above.
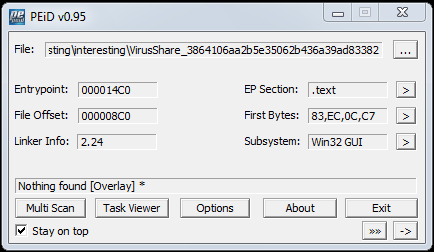
However, it has some strange section properties.
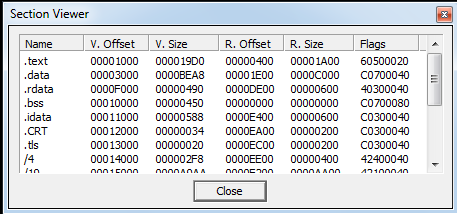
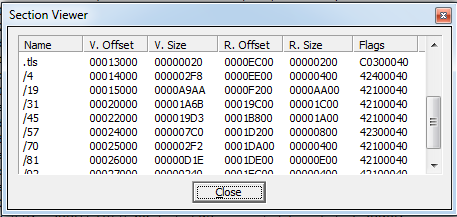
This executable has some special sections:
- .data: initialized data
- .idata: Import tables
- .rdata: read-only initialized data
- .text: exectuable code
- .tls section: thread local storage
- .CRT: a strange section that isn’t microsoft-specific
- Mystery sections with little data in their names
The .data section contained nothing of interest– just mangled junk. I’m sure it’s not actually junk, but I can’t derive anything meaningful from it.
The .idata section, however, does. This makes sense since it is supposed to store imports.
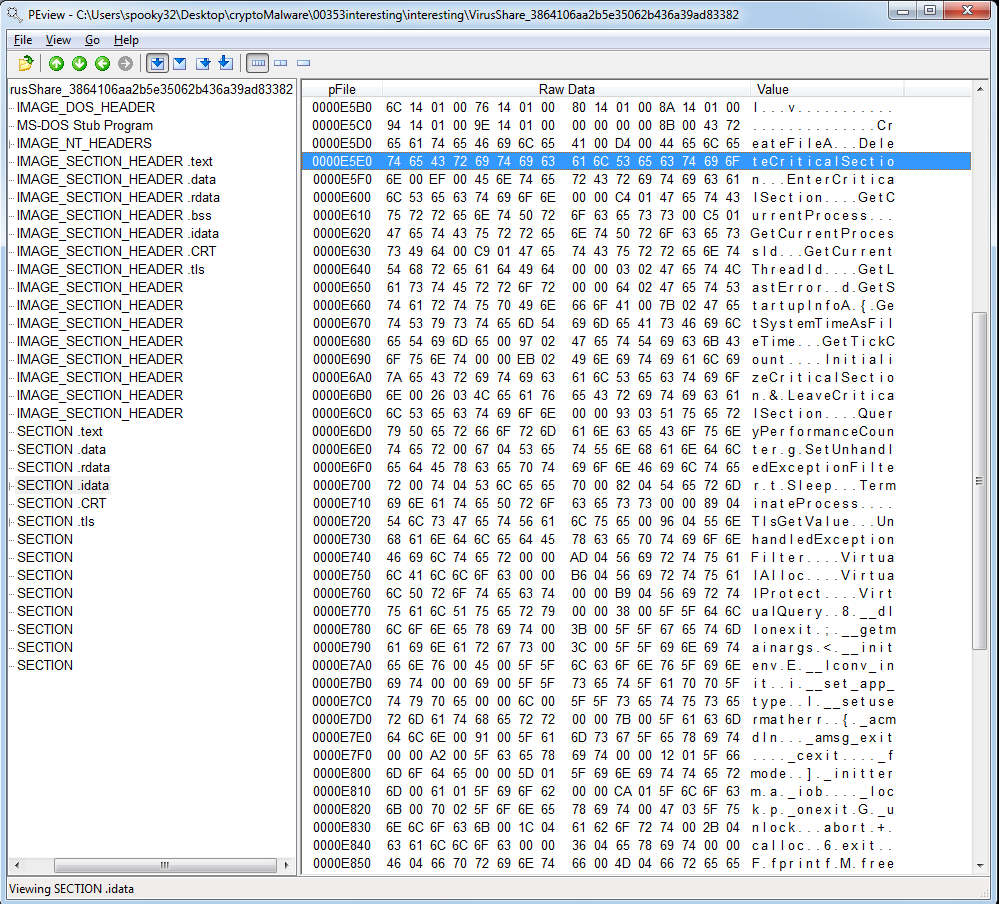
The .rdata section has some interesting content as well. It looks like error messages. Makes sense as to why it’s read only, I suppose.
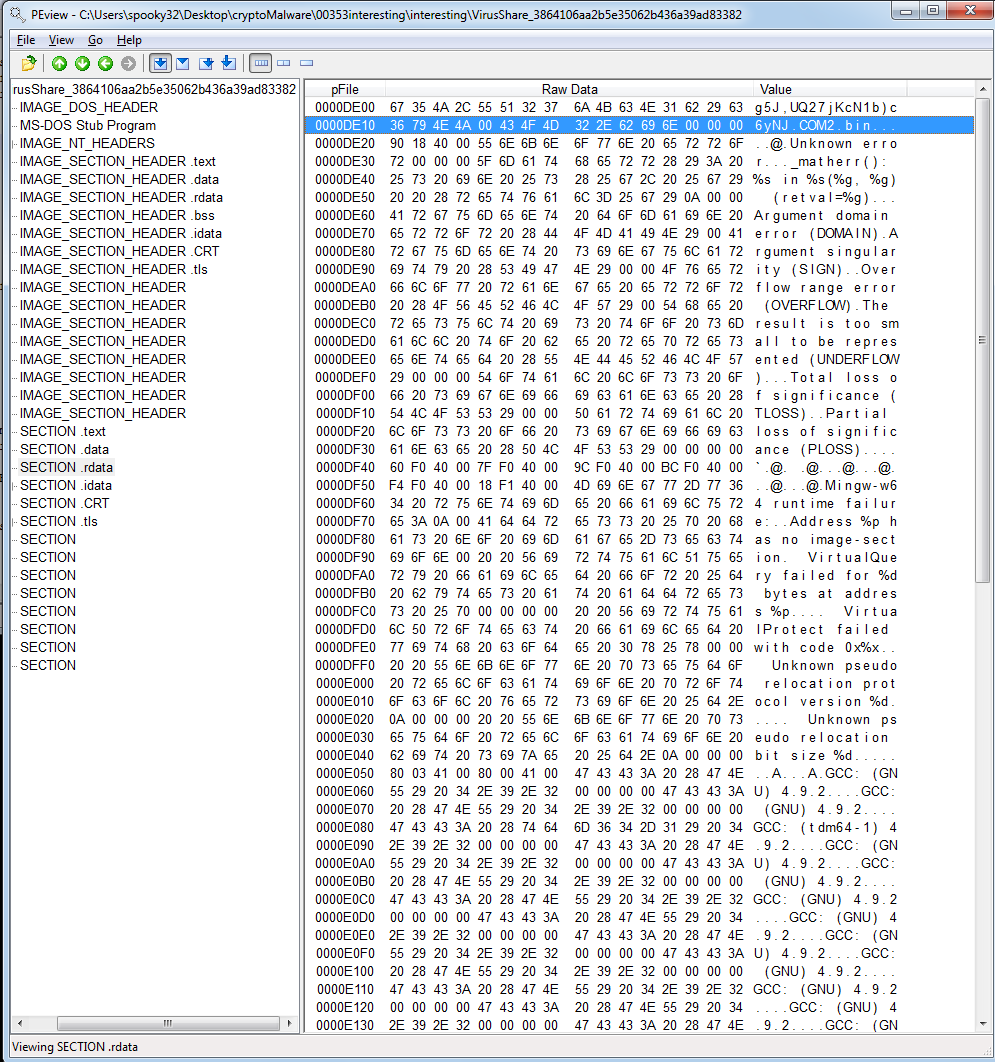
The .text section contains the entry point. Interestingly, this section is very, very small– both raw and virtual.
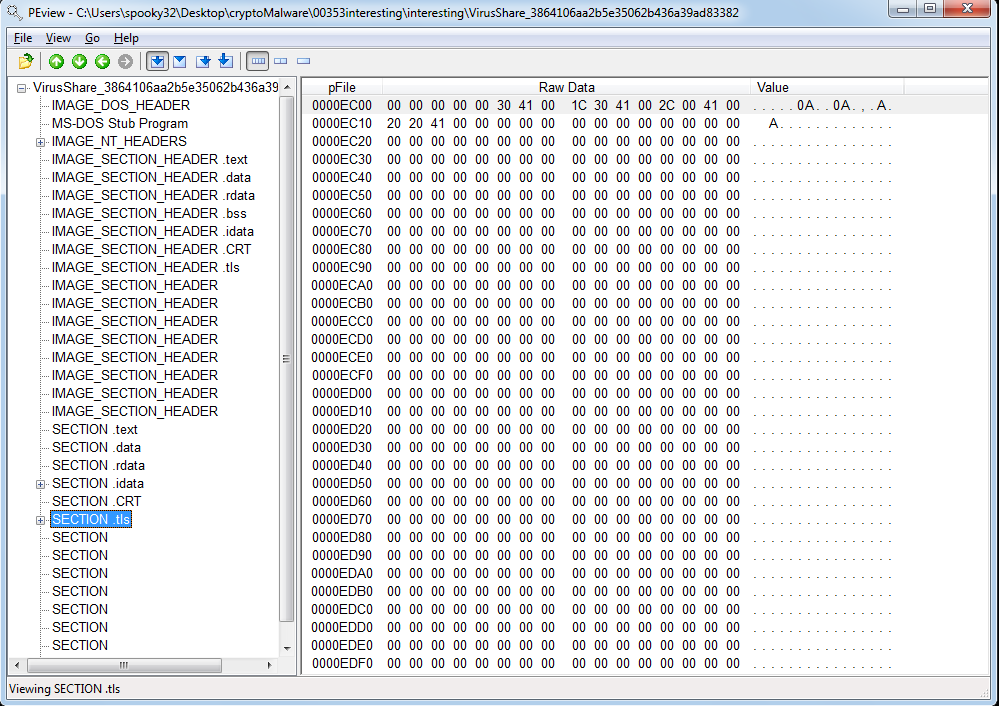
The .tls section is small and contains very little actual content. I don’t know if this is normal or not, but at the moment, I’m also not really that concerned about it.
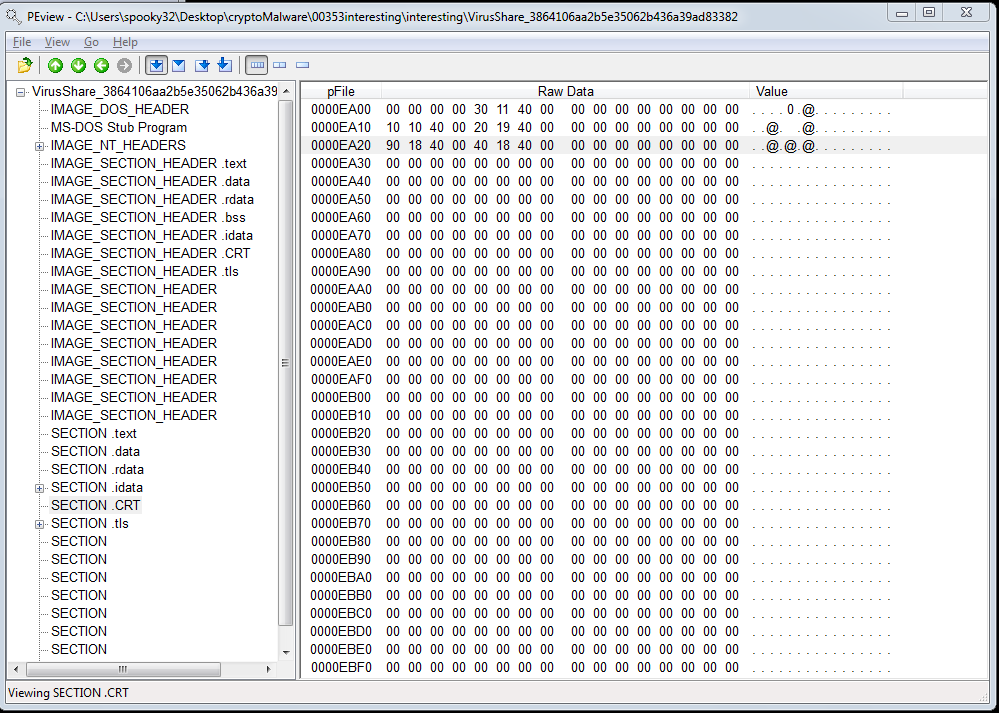
The .CRT section is very small and contains little content as well. However, I found this link that makes me suspect it has something to do with running C runtime functions. This suspicion is furthered by the fact that prior sections have lots of C-esque function names and error messages and etc etc.
The rest of the sections had some very interesting content. After scrolling through the second unnamed section for like four seconds, I noticed lots of different types of compilation strings apparently stored in this section. Lots of references to MinGW indicate that was the compiler used to create this executable. The highlighted portion of the next page tells me the path this dude had his source code on and that the code was named “natstart.c.”
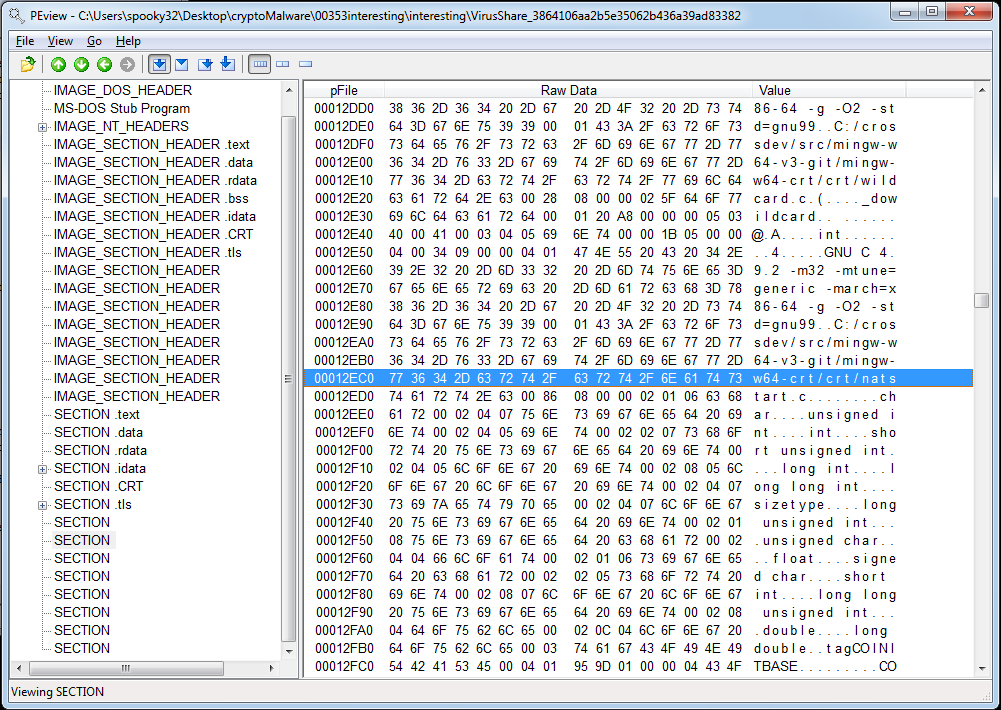
Other sections were hit or miss. Nothing immediately gave away that this file was malware, at least in my eyes. However, I think it’s fair to presume this file is not packed.
Looking at a purposely protected sample of malware
My last post is incomplete; it remains that way because I was defeated by the packer. The previous post features sample VirusShare_31adfc123d1b85d3f0d43f8401dcd042– a sample protected with Enigma Protector v1.1. Maybe some of what I observed by watching it partially unpack will help me understand what its metadata looks like.
I got distracted with looking at the file in PEview, however. I know that Ida tells you when the import table appears to be destroyed (which is often the case with packed malware). So I found where the import table is marked as being, according to the file headers:
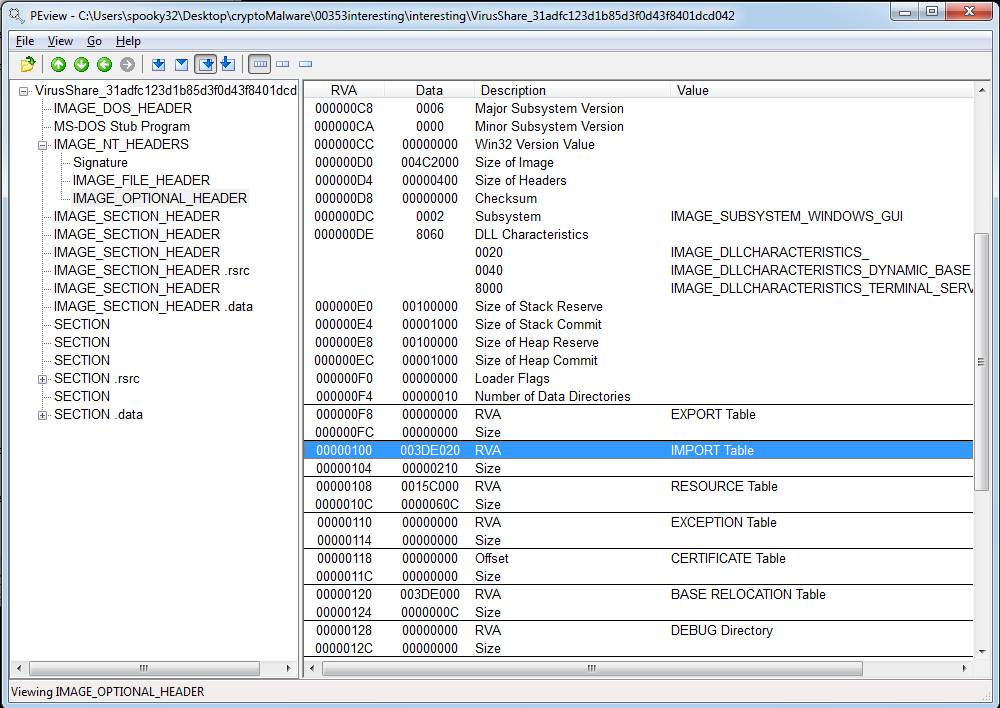
And headed to that part of the file, which was in an unnamed section:
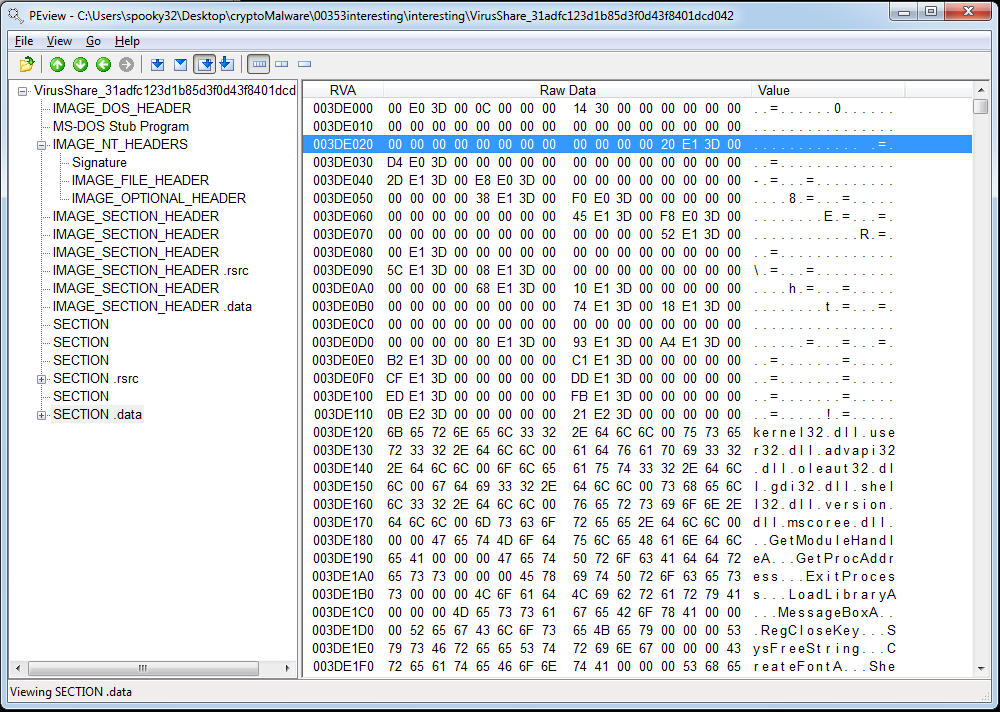
The imports just seem a little offset. Clearly there are some import strings a ways below. For comparison’s sake, this is what Notepad++’s import table looks like, at the address specified in its headers (that is, 0x1EC7B4):
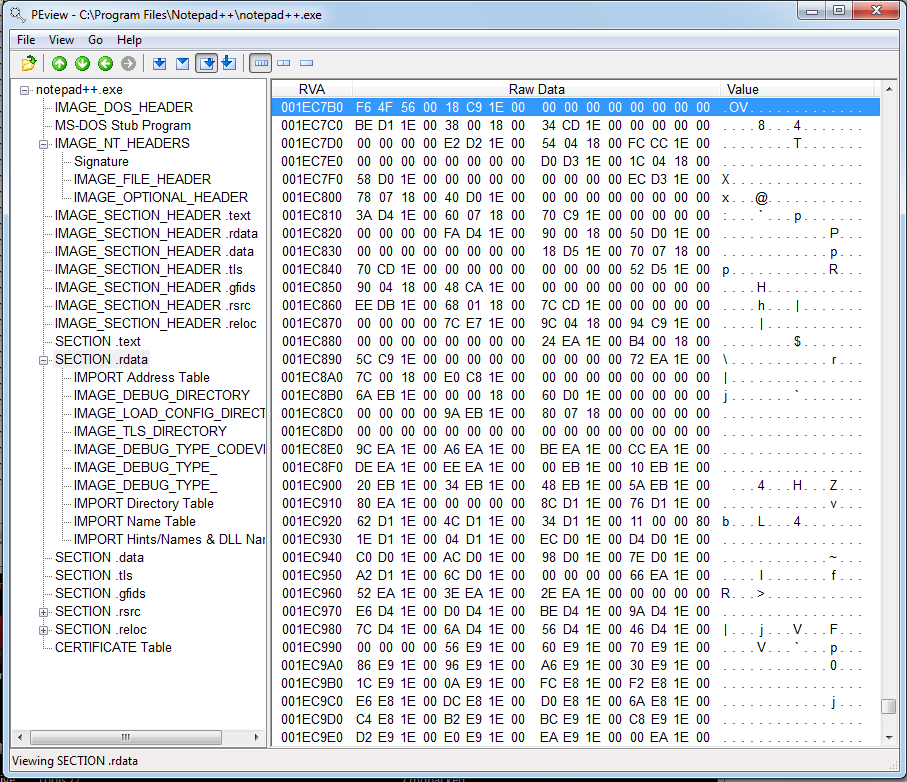
There’s nothing of any meaning there. However, scrolling down a little reveals MANY imports:
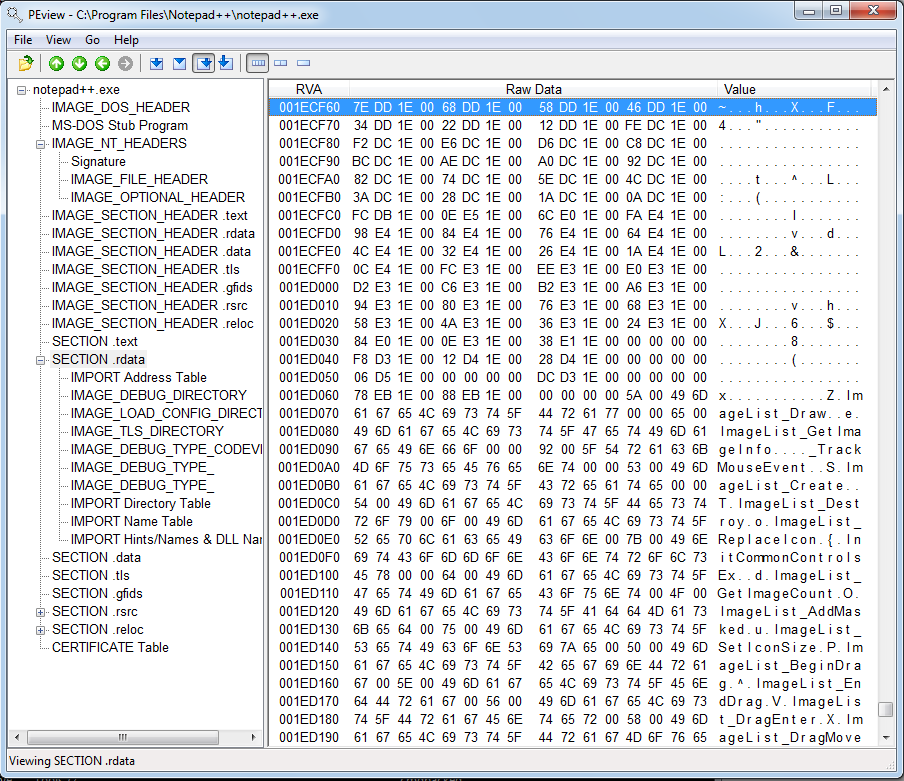
Again, for comparison, Wireshark imports start at 0x5b842c:
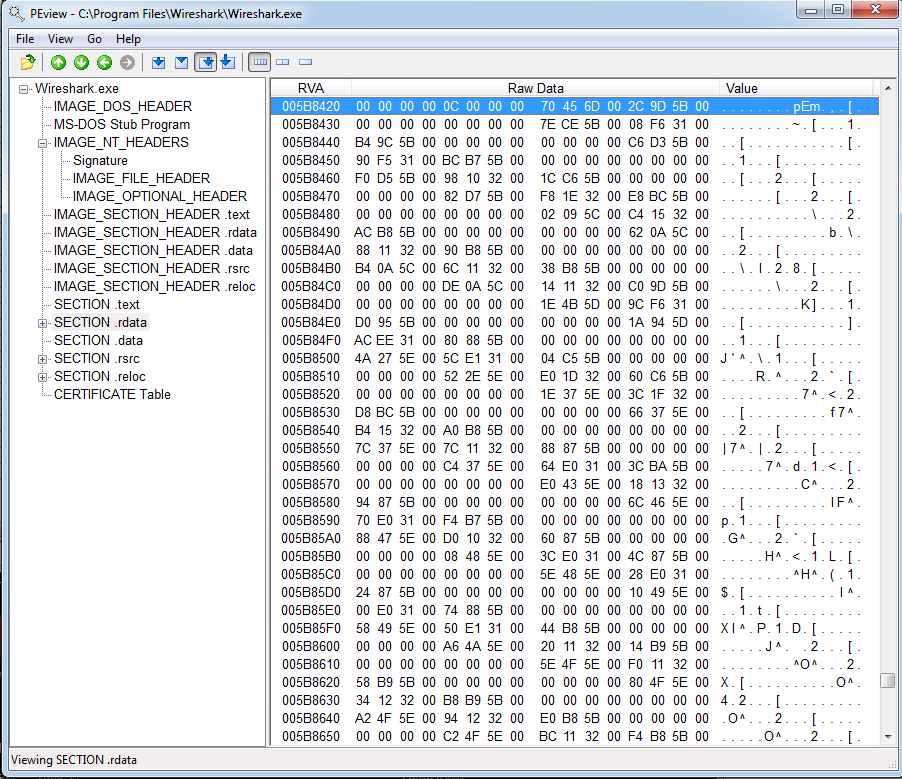
Unfortunately, I see no way to quickly identify a mangled import table from a clean one. Enough with PEview. I proceeded to look at the sections using PEiD:
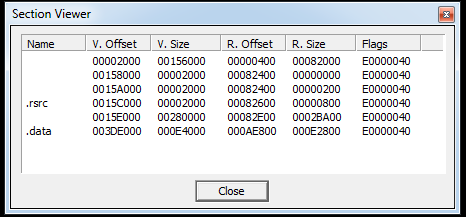
Yet again, we have sections with much larger virtual sizes than raw sizes. This seems to be a tried-and-true sign of packers (or at least ones that are applied to full exectuables and not the nasty partially-unpacking ones). If I had to guess, I should look for unpacked code in the unnamed section between .rsrc and .data because that section is MUCH larger than the rest. However, the first one doubles in size too…
Last post I found two unpacking loops that were simple and easy to follow. I believe these are unpacked in the second and third respectively unnamed sections. It would be interesting to follow the unpacking process in OllyDbg again and see if I can observe some notion as to if this is the case. Perhaps I’ll leave that to the next blog post.
Conclusion
This article was all about exploring the PE file structure and observing how packers manipulate the headers and data values to conceal, and therefore indicate, the existence of nefarious deeds. While I still have questions to answer, I believe this post was a great start to further understanding how all of this works together.
