I recently gained access to VirusShare and downloaded 65,536 samples (00353.zip, for those interested). Due to my inability to search the way I expected to be able to for specific kinds of samples on VirusShare’s website, I decided to download this massive corpus of malware and search for the samples I seek out within it. For my thesis, I need:
- Cryptomining malware executable assets/images/posts (i.e. not HTML scripts, which is what most of the malware in this corpus is)
- Banking trojans (emotets do the trick just fine)
- Ransomware (gandcrab, kryptik, etc)
- Maybe some adware
Now, when we download the samples, we are given the assets/images/posts named in the format VirusShare_[md5sum of file here]. That’s it. We have no notion as to what kind of malware each file is. So, I wrote a python script that used VirusTotal’s api to obtain known information on the samples, and store it in a local database. I store this information, per sample, in the database:
- file name
- file type (exe and kind of exe, html, word doc, pdf, etc)
- file hash (md5 or sha256)
- positives (i.e. how many antivirus vendors marked it as malicious)
- total (i.e. how many antivirus vendors have information on the file)
- results (i.e. the tags that antivirus vendors have assigned the file)
Doing this enabled me to search the malware metainformation database for the kind of malware I need. My goals are to run through this malware and identify mining routines within it. Overall, I strive to find what differs and what doesn’t differ between these mining executables, in hopes that I’ll be able to augment a visualization tool with features that help identify when its analyzing a cryptomining sample, as opposed to some other kind of sample. More on that later.
My search in the SQL database turned up 30 or so different samples of all kinds of executable formats. We have PE32 EXEs, PE32+ EXEs (i.e. 64-bit portable executables), ELF 64-bit executables, and some Windows DLLs. The first one of interest to me is VirusShare_31ADFC123D1B85D3F0D43F8401DCD042.
First thing first: CFFExplorer.
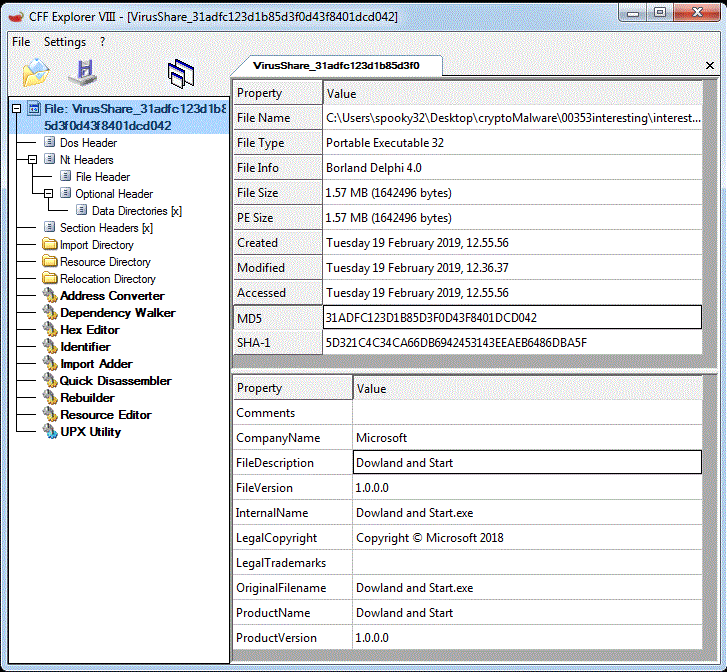
“Dowland and Start.exe”. Nice. After a quick google search, I found that Borland Delphi is a development environment for Pascal, released in 1998.
Next up, the obligatory VT search:
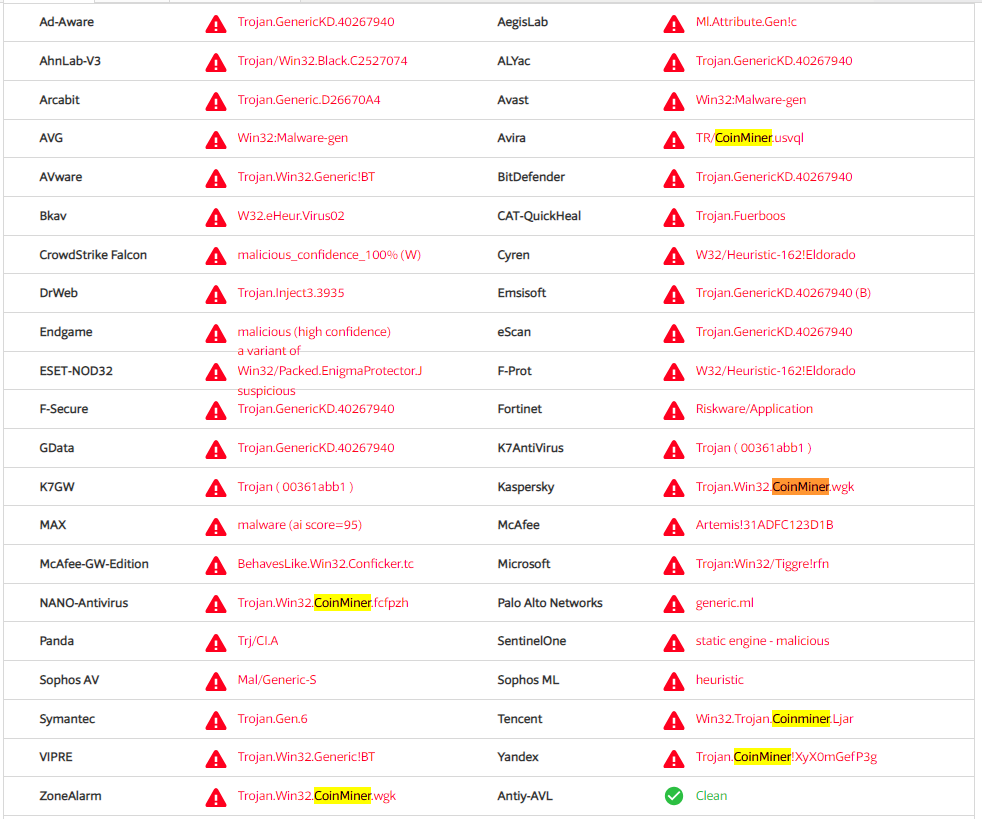
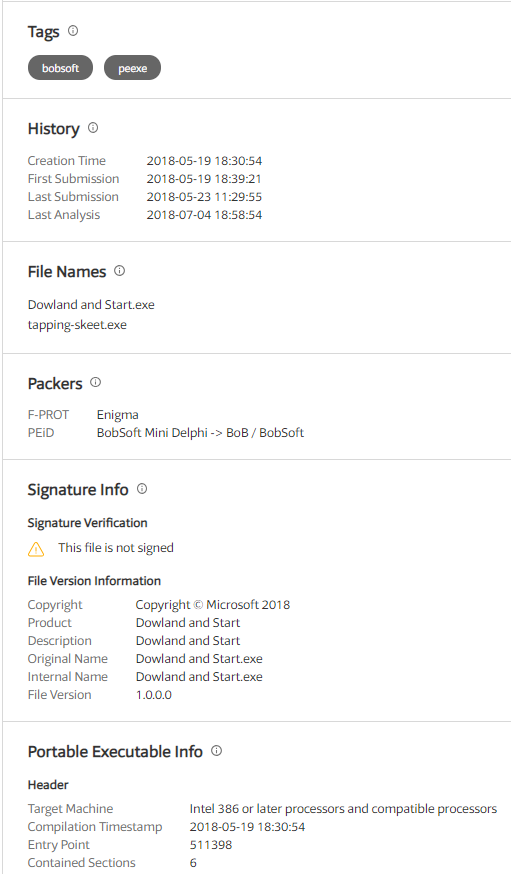
It looks like a coinminer, and it also looks packed (as VT hints towards). Sadly, PEiD helps confirm this. Furthermore, after clicking a link in a comment from some dude on VT, I found that hybrid-analysis further confirms it’s Enigma– specifically, v1.1 (wow this dude is out of date).
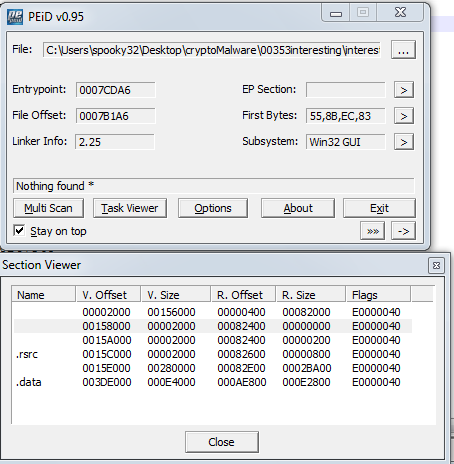
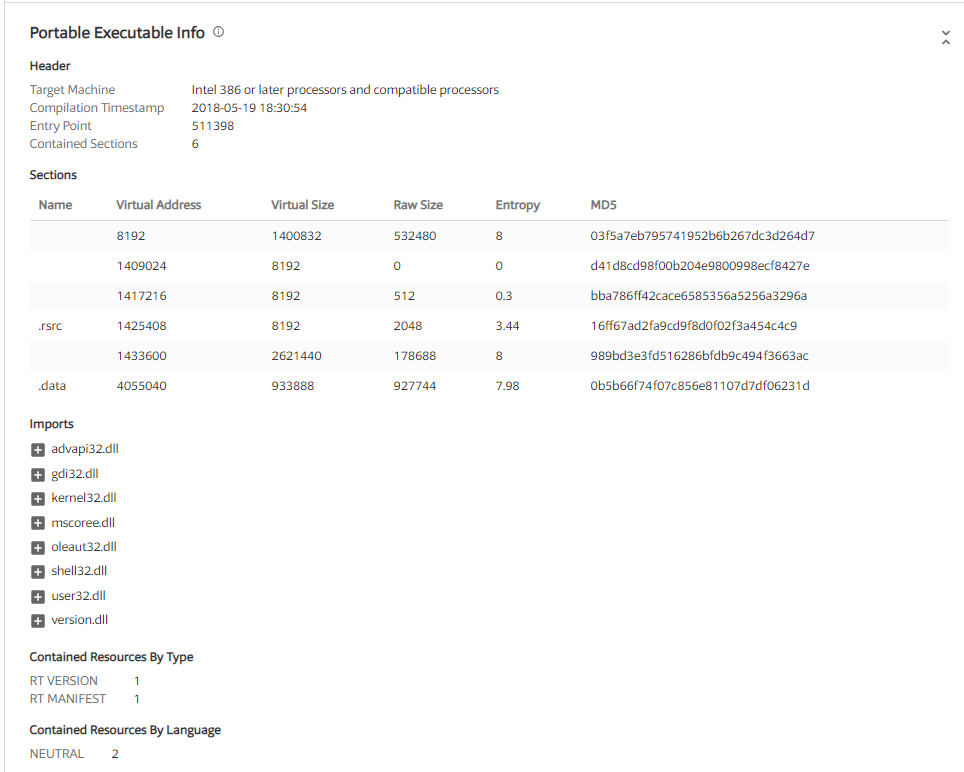
Raw section sizes of 0 and virtual section sizes of >0 are very suspicious. Opening it in Ida resulted in a notification that the Imports section is destroyed, which is further evidence that this thing is packed. However, Ida helped identify a potential saving grace:
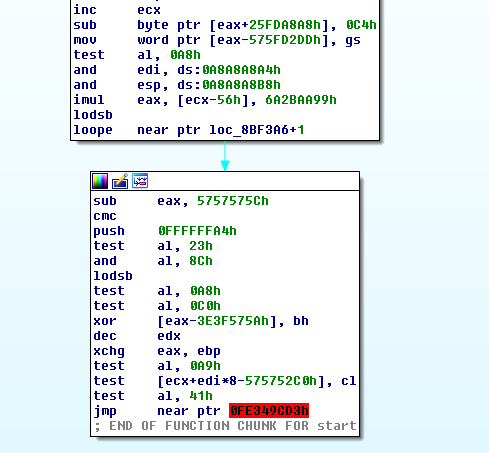
All the jump instructions visible to Ida were to local locations, except for the very last one, which jumps to who knows where. This is very exciting because it means OllyDbg’s “find OEP by Section Hop” feature may work!
But sadly, it did not. Enigma protector appears to be powerful. My mentors haven’t played with Enigma and I can’t find any easily available unpacking tools. Guess it’s time to try manually unpacking my first live sample!
I will be using OllyDbg to debug this. If you haven’t seen my posts on OllyDbg or my posts on unpacking, check those out.
Upon opening this in OllyDbg (while also having it open in Ida), notice the similarities between instruction addresses.
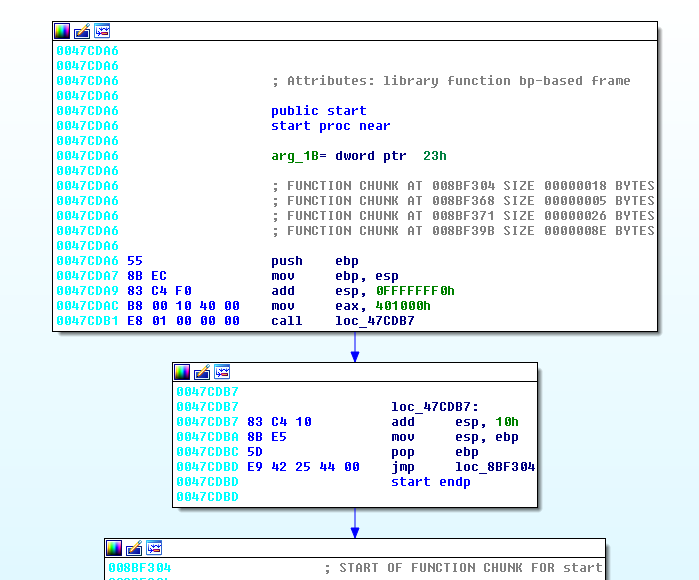
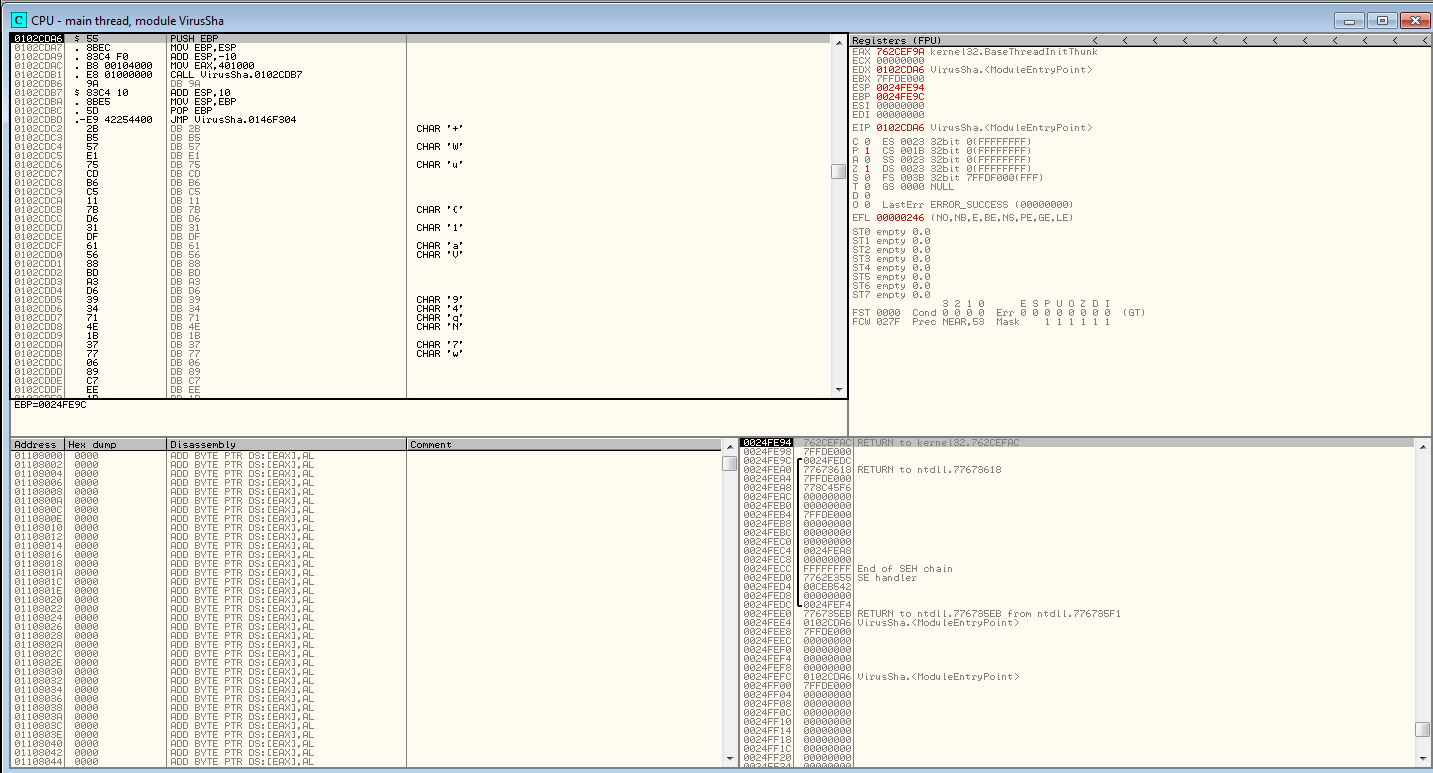
Thankfully, Ida and Olly’s addresses line up (at least relative to the last byte). Ida registers the first instruction at 0x74cda6 and Olly registers the first instruction at 0x102cda6. The first interesting bit of code occurs at 0xf388– our first XOR decode loop.
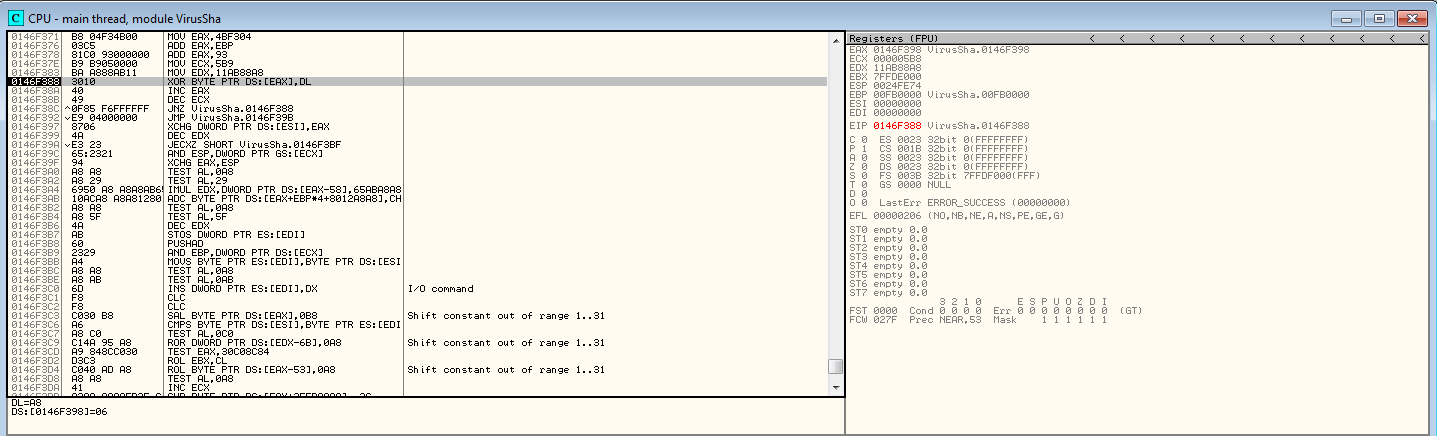
Note that this screenshot is after I have ran through one iteration of the loop. Things to notice:
- We XOR the contents of where EAX points to, with DL, 1 byte at a time.
- ECX contains how many bytes we decode.
- Decoded code begins starting at Olly address 0x146f397.
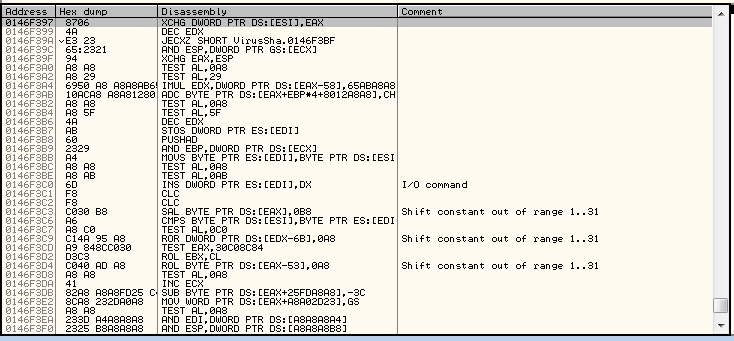
Before much has been decoded, notice the presence of garbage (as is indicated by processing the data as instructions and seeing that the instructions are .. meaningless):
After a few iterations, we see new instructions now exist.
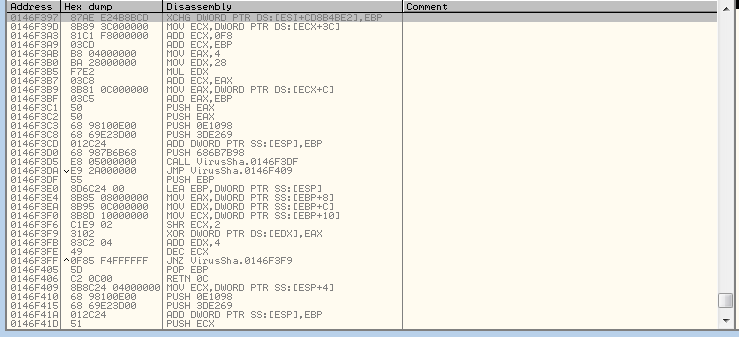
One big giveaway that this is important and meaningful code is that it has jump instructions relative to the general area that this code is being decoded into.
So, I set a hardware breakpoint on the jmp immediately after the JNZ and noted the final address of this loop’s unpacked code: 0x146f94F. Range: 0x146f397-0x146f94f; however we jump to 0x146f39b. Luckily after two instructions, the disassembly in the top left window and in the bottom left window match back up; a sign that the dump is disassembling instructions properly (and is not offset by disassembling in the middle of an instruction).
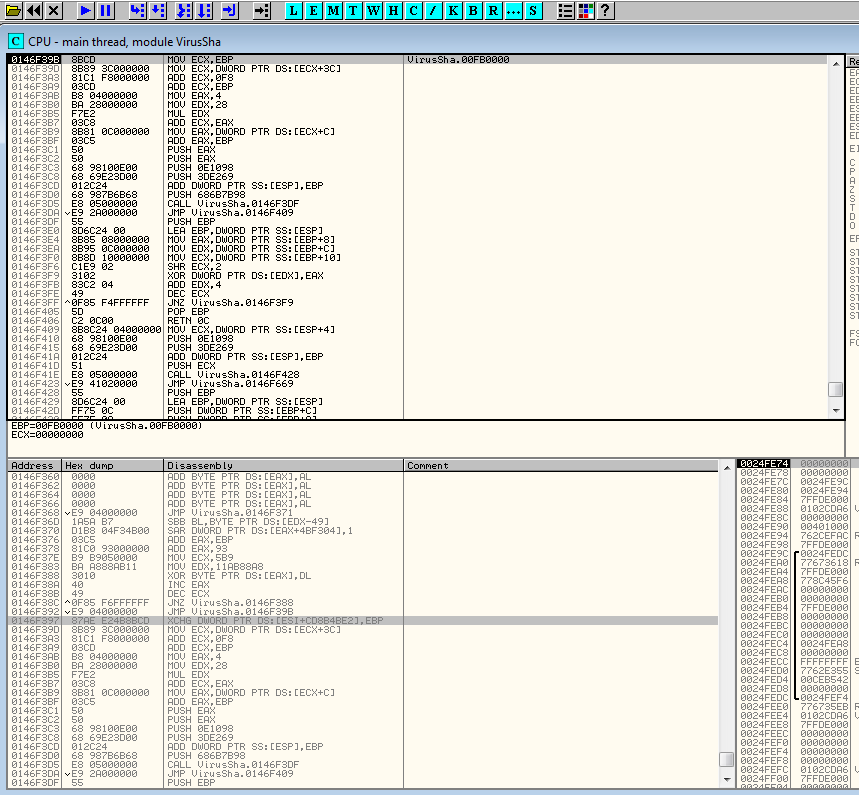
Follow on through, not really positive exactly what’s happening but also not caring… and we arrive at decode loop 2. This one decodes 4 bytes at a time, and a lot more! Thank goodness.
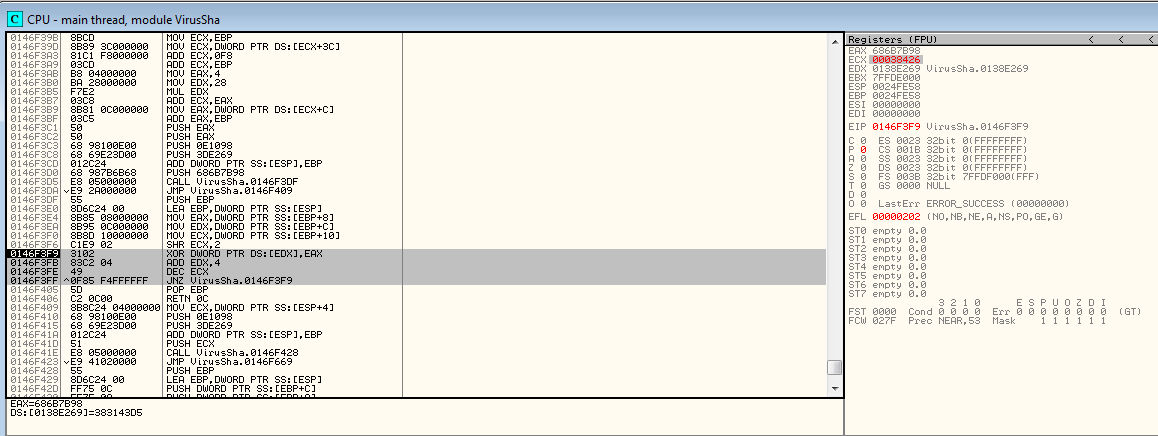
Range of decode: 0x138e269-(0x138e269 + (ECX = 0x38426 * 4))
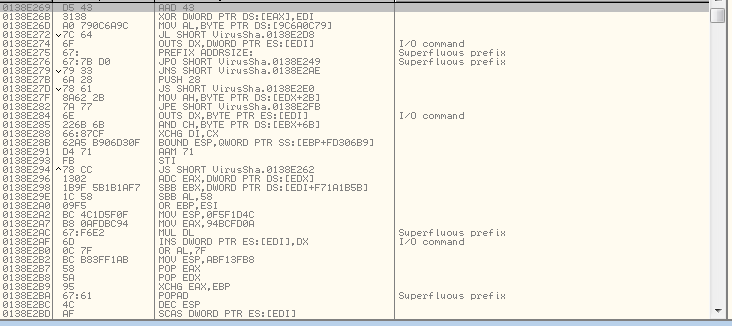
after some iterations…
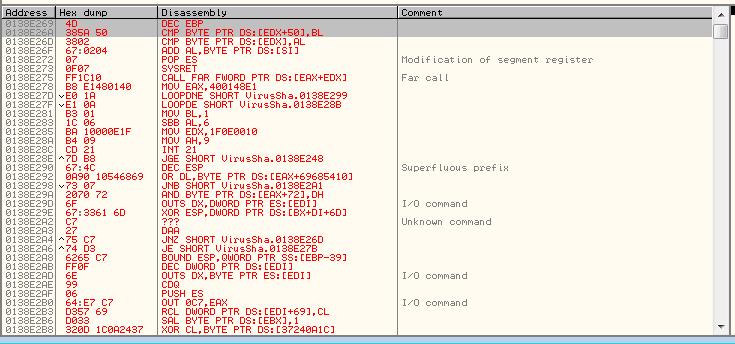
Sketchy. So I decoded the rest of it and broke at the instruction immediately after.
0x138e269-0x146f301 is the value of this decode loop’s range. Still below the previous unpacking loop’s range; that code has not been overwritten.
Following it a little more… it jumps to 146f4aa which looks an awful lot like a generic function prelude.
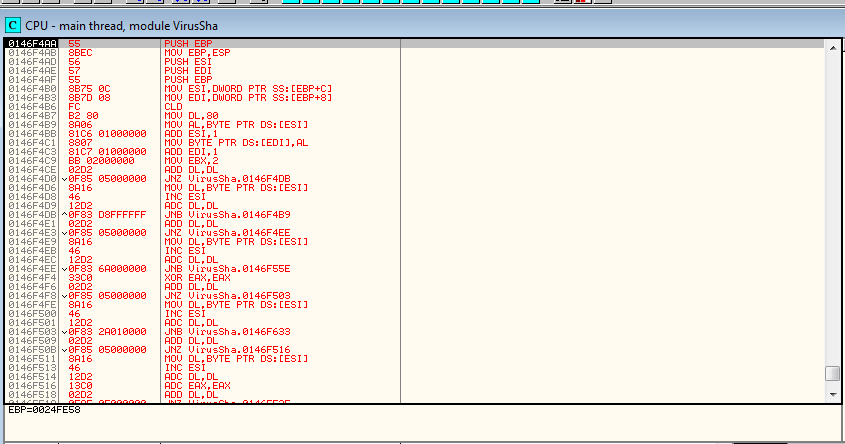
After this, things kind of go awry. It gets much harder to follow. It is modifying 110e000 and onwards (to about 110f000). Then it looks like another phase begins.
I noticed that for the last few thousand instructions, EIP never left the range 146f400-146f650.
146f4ce-ish: an add that is probably checked
notes
102cda6: start
0x110e000-0x110f000: mystery region. Not sure what’s happening but it’s being heavily modified by code in 146f400-146f650ish.
0x138e269-146f301: second unpacked region
0x146f397-146f94f: first unpacked region
